
Riconoscimento dei caratteri (OCR) con OCRFeeder
Riconoscimento dei caratteri (OCR) con OCRFeeder.
Vediamo, di seguito, come utilizzare – in ambiente Ubuntu Linux, un programma in grado di interfacciarsi con il motore OCR oggi sviluppato da Google. Il software si chiama OCRFeeder, è distribuito con licenza GNU GPLv3 e funge da interfaccia grafica per Tesseract ed altri motori di riconoscimento ottico dei caratteri. Tra le principali abilità del software, citiamo le funzionalità volte a mantere – per quanto più possibile – la struttura originale del documento acquisito tramite scanner. Il documento prodotto da OCRFeeder può essere salvato direttamente come ODT (OpenDocument Format), formato supportato dalla suite OpenOffice.org.
Per installare OCRFeeder in Ubuntu, è sufficiente aprire il Software Center (menù Applicazioni, Ubuntu Software Center), digitare ocfeeder nella casella di ricerca in alto a destra quindi premere il pulsante Installa ed attendere il completamento dell'operazione.

Il pacchetto d'installazione include anche il motore OCR Tesseract che risulterà da subito disponibile.
OCRFeeder non riesce, almeno per il momento, ad interfacciarsi con lo scanner collegato al personal computer per l'acquisizione dei documenti da sottoporre ad OCR. Il programma, invece, può ricevere in input una o più immagini in diversi formati. Prima di avviare OCRFeeder, quindi, si dovrà provvedere ad acquisire le pagine sulle quali si desidera effettuare il riconoscimento ottico ricorrendo al software dello scanner. Le immagini ottenute potranno poi essere successivamente passate ad OCRFeeder per l'elaborazione.
Dopo aver eseguito il programma (menù Applicazioni, Ufficio, OCRFeeder), cliccando su File, Aggiungi immagine si potrà inviare ad OCRFeeder una singola immagine acquisita da scanner. Se il documento da sottoporre al riconoscimento ottico dei caratteri è composto da più pagine e tutte le immagini corrispondenti sono state salvate in un'unica cartella, sul disco fisso, ricorrendo al comando Aggiungi cartella è possibile specificare un'intera directory alla quale attingere.
Interessante anche la funzione Importa PDF, utilissima nel caso in cui si abbia a che fare con PDF non modificabili contenenti testi acquisiti mediante scanner e salvati nel formato di Adobe.
Tutte le immagini ed i documenti PDF che si passeranno ad OCRFeeder andranno a formare un "progetto" che potrà essere salvato come file a sé stante per successive elaborazioni.

Si provi a selezionare una qualunque parte del documento aiutandosi con i pulsanti per l'ingradimento (zoom in e zoom out), gli ultimi due della barra degli strumenti.

Cliccando sul pulsante OCR, posizionato nella colonna di destra, OCRFeeder richiederà il riconoscimento dei caratteri per la porzione di testo evidenziata. Il motore OCR utilizzato è quello indicato accanto al pulsante OCR (quello predefinito è, appunto, Tesseract).
Si provi però a cliccare sul menù Strumenti, Ritaglia ed fare clic sul pulsante Anteprima.
OCRFeeder provvederà così ad applicare alcune ottimizzazioni all'immagine in corso di elaborazione in modo da facilitare il riconoscimento dei caratteri e a non indurre il motore OCR in errore. Dopo aver selezionato OK, si noterà come il documento sia notevolmente più leggibile, libero da quelle imperfezioni che sempre caratterizzano il materiale acquisito dallo scanner (soprattutto nel caso di fogli di giornale e riviste).
Ad operazione conclusa, il software avrà anche selezionato – in modo del tutto automatico – i blocchi di testo e le immagini rilevate nel documento.
Nel caso di documenti con una formattazione piuttosto complessa, suggeriamo di non avventarsi subito sul menù Documento, Riconosci documento. Sarebbe invece preferibile evidenziare (mantenendo premuto il tasto sinistro del mouse) le varie aree contenenti il testo quindi cliccare il pulsante OCR (colonna di destra; i vari passaggi potrebbero richiedere qualche istante di attesa, a seconda della quantità di testo selezionato).
Le aree del documento occupate dalle immagini debbono essere esplicitamente indicate: basta selezionarle, portarsi nella colonna di destra di OCRFeeder e scegliere l'opzione Immagine.

In corrispondenza dell'opzione "Test" manca una "o": leggasi quindi "Testo" (si tratta della scelta predefinita che permette di indicare una porzione del documento come testo da inviare al motore OCR).
A questo punto, è possibile esportare il documento sotto forma di file ODT cliccando sul terzo pulsante, da sinistra, della barra degli strumenti (Esporta in ODT; oppure menù File, Export..., ODT).
Come "bonus tip" spieghiamo come sia possibile aggiungere altri motori OCR, alternativi a Tesseract. Innanzi tutto, è necessario avviare il "Software Center" di Ubuntu quindi digitare gocr nella casella di ricerca. Premendo il pulsante Installa si aggiungerà il nuovo motore OCR.
Stessa operazione può essere effettuata per installare un terzo motore, digitando – nella casella di ricerca del "Software Center" ocrad.
Per aggiungere i due motori in OCRFeeder basterà cliccare su Strumenti, Libreria OCR, sul pulsante Riconosci, selezionare le caselle corrispondenti a gocr ed ocrad quindi premere Aggiungi.
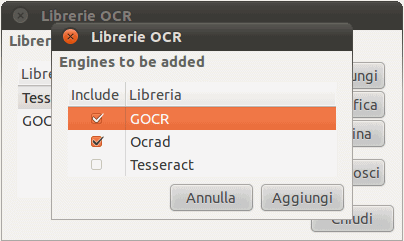
Come si potrà verificare selezionando una porzione di testo, scegliendo un motore diverso da Tesseract quindi cliccando sul pulsante OCR, è di solito Tesseract a fornire i risultati migliori, nella maggior parte delle situazioni.